内存不够时,替代sns.countplot()的实现方法
内存不够时,替代sns.countplot()的实现方法
最近做EDA的的时候会存在这样一种情况,数据量过大时,直接使用sns.countplot()内存很容易直接被榨干掉。
暂时没想清为什么会直接占用那么多内存,应该去StackOverflow提个Q的。
不过想了下又查了下StackOverflow,应该有用df.value_counts() 和 matplotlib来实现sns.countplot()的实现方法,如此,What is Matplotlib's alternative for countplot from seaborn?
引用自StackOverflow,ImportanceOfBeingErnest
Say you have this data:
1 | import numpy as np; np.random.seed(42) |
You can plot a countplot in seaborn as
1 | import seaborn as sns |

Or you can create a bar plot in pandas
1 | df["Sex"].value_counts().plot.bar() |
.plot.bar()")
Or you can create a bar plot in matplotlib
1 | counts = df["Sex"].value_counts() |
.index, df[Sex].value_counts().values)")
Reference
如何指定xtick在一个特定的范围
在做EDA的时候,会有种情况,时序数据所做的plot的x-axis会存在过于密集的情况,如下

所以我们要做的就是只用将数据所在范围按一定频率切分开就行了,如这个Q,[how to change the xticks to a specific range [duplicate\]](https://stackoverflow.com/questions/56713197/how-to-change-the-xticks-to-a-specific-range) 和 Changing the “tick frequency” on x or y axis in matplotlib?
分别引用自StackOverflow用户 Heike和Alexandre B.并作出了一定修改。
在comment和answer处提供了两种解决方案:
添加一行代码
plt.xticks(range(9, 40, 10), range(10, 41, 10))这里第一个参数是是将xtick分块显示,第二个参数是各个分块处显示的数字.(这里原来的数据找不到了,就用了answer中随机生成的数据为例子).
例子:
1
2
3
4
5
6
7
8
9
10
11# Your data to count
y = np.random.randint(0,41,1000)
# Create plot
fig, ax = plt.subplots()
sns.countplot(y)
# Show graph
plt.xticks(range(0, 41, 10), range(0, 41, 10))
plt.xlabel('user_id')
plt.show()
但是假如将第一个参数设置的分块范围超过数据已有的范围,则会在plot超出数据已有范围处显示出一段blank。

One way is to define the labels on the x-axis. The
set_xticklabelsmethod frommatplotlibmodule do the job (doc). By defining your own labels, you can hide them by setting the label equal to''.By defining your own labels, you need to take care that they are still consistent with your data.
Here is one example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# import modules
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
#Init seaborn
sns.set()
# Your data to count
y = np.random.randint(0,41,1000)
# Create the new x-axis labels
x_labels = ['' if i%10 != 0 else str(i) for i in range(len(np.unique(y)))]
print(x_labels)
# ['0', '', '', '', '', '', '', '', '', '',
# '10', '', '', '', '', '', '', '', '', '',
# '20', '', '', '', '', '', '', '', '', '',
# '30', '', '', '', '', '', '', '', '', '', '40']
# Create plot
fig, ax = plt.subplots()
sns.countplot(y)
# Set the new x axis labels
ax.set_xticklabels(x_labels)
# Show graph
plt.show()
Reference
- [how to change the xticks to a specific range [duplicate\]](https://stackoverflow.com/questions/56713197/how-to-change-the-xticks-to-a-specific-range)
- Changing the “tick frequency” on x or y axis in matplotlib?
- matplotlib.axes.Axes.set_xticklabels
将DataFrame中的数据以表格的形式另存为图片
将DataFrame中的数据以表格的形式另存为图片
在上次按序输出关联矩阵的blog中有了将DataFrame中的数据以表格形式另存储为图片的想法。
起初,Google了在StackOverflow上找到了相关问题,并将代码修改应用于Titanic的数据上,具体如下:
1 | from pandas.plotting import table |

但是,发现另存为的图片极为模糊,再思考并查询相关文档未果后,并在StackOverflow上提出了相关问题,发现是因为没有设置合适的dpi参数,故设置合适的dpi参数并修改代码如下:
1 | from pandas.plotting import table |

Reference
在matplotlib的一个figure中画多个subplots
How to save a pandas DataFrame table as a png
How to make picture clear when saving the table of DataFrame as a picture
以DataFrame的形式按序输出关联矩阵(correlation matrix)
以DataFrame的形式按序输出关联矩阵(correlation matrix)
一般来说在做EDA的时候,我们都是输出相关矩阵的热力图或者是以表格形式输出。
但是我在Stantar 2019的一个kernel见到了按序输出关联矩阵系数的代码,故在此基础上进行了一定修改,实现了一个自己的code snippet.
具体例子见下:(此处数据采用Titanic in Kaggle)
1 | train_corr = train_df.drop(['PassengerId'], axis=1).corr() |
1 | # 设置热力图尺寸为(20, 12) |
/04/23/以DataFrame的数据格式按序输出关联矩阵(correlation%20matrix)/heatmap.jpg "heatmap")
1 | corr = train_corr.abs().unstack().sort_values(kind='quicksort', ascending=False).reset_index() |
/04/23/以DataFrame的数据格式按序输出关联矩阵(correlation%20matrix)/correlation_matrix_HD.jpg "correlation_matrx")
一般是设置ascending参数,来看你是想要按序输出高或低相关度.
这里feature数量比较少,故直接输出,一般是corr调用tail()或者head()来输出该顺序中的后或前几个相关系数。例如:
1 | corr.tail(4) |
下一篇会在再讲下,如何将Pandas.DataFrame的表格存储为图片,这也是在写这篇blog过程中的一点idea的实现.
Reference
在matplotlib的一个figure中画多个subplots
在一个figure中画多个subplots
在做EDA和Data Visualization中常常会用到的一个code snippet,在这里以kaggle上的titianic数据为例子:
1 | # 先导入packages |
1 | # 导入数据 |
其中部分代码也可重写为如下:
1 | fig, ax = plt.subplots(nrows=1, ncols=2) |

也可以根据修改nrows, ncols参数来适用多行多列的情况:(这里举得这个例子只是为了举例而举例,没有过多实际意义)
1 | fig, ax = plt.subplots(nrows=2, ncols=2) |
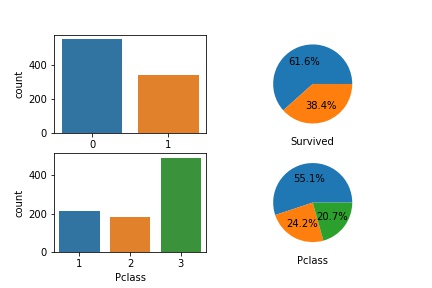
当然也可以用循环来实现,在此不对这举例了。
中间还有2个小插曲,就是我实现的时候,发现ax[0, 0]的subplot没有x_label,所以还去StackOverflow上面提了个Question,发现仅仅是被hidden住了,加上一行plt.tight_layer()代码即可。
1 | fig, ax = plt.subplots(nrows=2, ncols=2) |
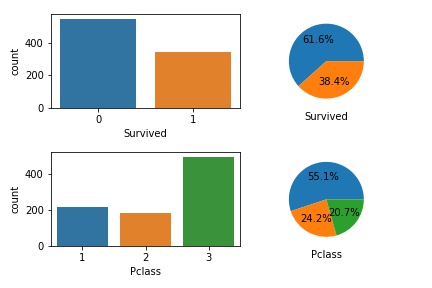
还有就是hexo插图片时,若用markdown语法,说是文章在首页无法显示图片,点进去后仍可,所以只可采用最好用标签插件语法来实现,例如:

Reference
why-is-matplotlib-plotting-my-circles-as-ovals
how-to-set-the-labels-size-on-a-pie-chart-in-python
set-xlabel-is-in-invalid-in-ax0-0-when-drawing-4-subplots-in-one-plot
Stantar 2019有感
Stantar 2019有感
看了很多个top solution,尤其是金牌区域的。
给我感觉在这个比赛中的几个重要的magic有:
- frequency coding;在对于匿名数据或者categorical feature上,可以先试着这样做下,一般是会提升local CV之类;
- fake data;对于training set和testing set中的unique value的数量明显不同,让人怀疑testing set中的数据包含伪造数据。对于testing set中的伪造数据进行删除即可。List of Fake Samples and Public/Private LB split
- independent feature;利用feature间的相互独立性,在用LightGBM训练时,只对某一特征训练,故有200个lgb classifier再对预测结果进行简单的simple linear blending。a single model using all features vstacked that is enough for a top20 on Private
感受颇深的是对于这些magic,一是自己确实没有通过EDA来发现到,能力有限;二是其实在kernel和discussion中都有多多少少提及到,自己未引起重视又或者不知如何是好。
个人主要感觉还是:
- 在EDA方面考虑得不够到位,而且可以利用:
- Local CV和LB的提升上差异来分析是哪里的问题,然后解决并使得Local CV和LB的提升近似。比如此次中,一开始无论local CV提升有多高,LB都会锁在9.001上。而解决到fake data的存在后,local CV提升,LB也会随之提升,使得LB锁在9.001的情况不复存在;
- 可以根据kernel和discussion区域中,若在新的发布后,上的存在着许多人的大幅度增长,则说明某个kernel或discussion揭露了magic;
- Model这一块也是有问题,很明显在NN上存在很多问题,尤其是现在去看top solution中开源的NN代码,会存在很多逻辑看不太懂的情况;
- Parameter Tuning上面也有问题,除了最基本的Grid Search和Random Search外,对于Bayesian optimization没有理解且无法应用出来。Chris这个discussion给了很多inspirations;
- 对于Data Science这块Coding能力上也存在着问题,不能很流畅的阅读代码逻辑;
- 这个比赛没有用到Feature Selection, 然而这块也是我的弱项;
- 在最后如何选取2个the most robust model用于提交到PB上也仍未解决。
不过感觉还是收获了不少,在我上述几方面加强后,还是需要回来reiview Stantar这个比赛的各个solution。
Reference
Gold Medal Solutions of Stantar 2019
List of Fake Samples and Public/Private LB split
Giba: a single model using all features vstacked that is enough for a top20 on Private
一些学习计划
学习计划
reivew知识,夯实基础。按着sklearn中User Guide中的6个模块来review一遍文档和其中涉及到的相关知识。不过不会以完整的罗列出来全部内容的形式来做,这样就不符合DRY原则了(笑),只打算列出各个API中涉及到的不熟悉的知识点的相关知识,又或者是相关链接,自己做一定的归纳总结。
具体来说就是:
- 理论知识上,在学习到一定程度下,留下学习到的相关链接,总结自己的理解;
- 代码实现上,在完全不熟悉或者理解不够透彻的情况下,需进行一定量的coding(暂不打算开源);
- 主要方向上,主要围绕
Supervised Learning,Model selection and evaluation,Dataset transformations,Unsupervised Learning这4个模块进行,除此之外对于XGBoost,LightGBM,CatBoost等Kaggle常见模型进行复习。 - 估计耗时:1个半月-2个月
继续实战。
具体目标有:
完成对Stantar customer transaction prediction 2019的kernel和discussion的学习,并在别人给出的hints下,自己实现一个top 1 % kernel并开源出来。
在Don't Overfit 和TMDB Box Office Prediction 两个Plaground competition中争取进去Sliver Zone,并在Don't Overfit 结束并学习完后赶紧进入Jigsaw和Earthquake的两个比赛中去。
review Matplotlib和seaborn两个package,根据Kaggle开源kernel熟悉可视化部分。之前这块太弱了,严重影响了EDA的能力。
review Numpy和Pandas两个package,加强数据处理的能力。
估计耗时:
- 10-15天
- 持续2个月+
- 15-20天
- 10-15天
Book Reading&Thesis Learing
具体目标有:
- reivew线代(之前被搁置过)。把UTM-Applied-Linear-Algebra-and-Matrix-Analysis这本书剩下的地方内容+课后带答案的题仔细刷一遍(之前搁置到50%);
开PRML/ESL/MLAPP的坑。开Boyd的凸优化的坑。开NLP的坑。开Stanford ML相关公开课的坑- 估计耗时:2-3天一节,争取1.5个月内review完UTM这本线代书,再考虑开什么坑比较合适...
将这些任务同时进行,争取2个月之内完成这些目标,中间老板可能会有各种任务,最多不要拖过2周。在大部分结束前1-2周,会定制新的计划。
杂谈-为什么要搭一个blog
为什么以前不搭一个blog?
先谈谈为什么一起没这么个念头,主要有以下几点:
- 不想写些看上去很厉害其实没什么用的东西。
- 不想写些拾人牙慧的东西。
- 不想写些随便Google两下,或者看看两眼官方文档就能搞懂的东西。
- 写blog组织语言起来其实很费时。
而在有的网站上充斥着大量的这类内容,当然不是说没有“金子”在其中,只不过都被“垃圾”掩埋住了,所以在我觉得我不能输出一份没有任何错误的干货下,并不打算输出自己的知识。
为什么现在又搭了一个自己的blog呢?
无论是学业,还是生活都遭遇了很多糟心事,总得来说以下几个原因:
- 学习状态一直受挫,到现在为止都很难维持住我以前的最佳状态(每天8-10小时有效学习时间)。导致有些东西学了查,查了用,用了忘,忘了又查的循环之中,低效率甚至无效率学习时间过多。我得找个地方记住这些常常需要review的问题。
- 刚参加的一场Kaggle比赛,最后比赛结束,结果从Public LB top 7%跌到Private LB top15%。很受打击,感觉自己学的东西很不扎实。用荀子《劝学》中的一句话来说就是“蚓无爪牙之利,筋骨之强,上食埃土,下饮黄泉,用心一也。蟹六跪而二螯,非蛇鳝之穴无可寄托者,用心躁也。”。我得沉下心来,所以我决定找个地方记录下这个过程。
- 常常写blog,可以刷下GitHub的contributions次数,让生活充满绿色(笑),通过这个激励自己。
所以呢?
所以,可能我大概率可能在未来会输出一些我曾认为的“垃圾“。
Never mind,